

There is a Group Post By Connor on LinkedIn in Oracle Senior DBA Group, showing the links to access ASKTOM Best Posts and Oracle Magazines from https://asktom.oracle.com/pls/apex/f?p=100:9
Here is the Code Snippet that helps you to download all the Posts and Magazines as HTML files as your choice of Destination in your local file system .
Snippet To Download TOM KYTE Posts
import requests
from bs4 import BeautifulSoup
import string
import os
import urllib.request, urllib.error, urllib.parse
import sys
def Download_ASKTOM_files(path,url,enc,title):
try:
response = urllib.request.urlopen(url)
webContent = response.read().decode(enc)
os.makedirs(path+'\\'+ 'ASKTOM', exist_ok=True)
n=os.path.join(path+'\\'+ 'ASKTOM',title +'.html')
f = open(n, 'w',encoding=enc)
f.write(webContent)
f.close
except:
n1=os.path.join(path+'\\'+ 'ASKTOM_'+'Download_Error.log')
f1 = open(n1, 'w',encoding=enc)
f1.write(url)
f1.close
reqs = requests.get("https://asktom.oracle.com/tomkyte-blog.htm")
soup = BeautifulSoup(reqs.text, 'html.parser')
for link2 in soup.select(" a[href]"):
src=link2["href"]
durl='https://asktom.oracle.com/'+src
tit =link2.get_text().replace(string.punctuation, " ").translate(str.maketrans('', '', string.punctuation))
print(tit.replace(" ","_"),durl)
Download_ASKTOM_files("c:\\Users\\....\\Downloads\\blogs\\",durl,'UTF-8',tit.replace(" ","_"))
Snippet to Download Magazines
import requests
from bs4 import BeautifulSoup
import string
import os
import urllib.request, urllib.error, urllib.parse
import sys
def Download_ASKTOM_files(path,url,enc,title):
try:
response = urllib.request.urlopen(url)
webContent = response.read().decode(enc)
os.makedirs(path+'\\'+ 'ASKTOM_MAG', exist_ok=True)
n=os.path.join(path+'\\'+ 'ASKTOM_MAG',title +'.html')
f = open(n, 'w',encoding=enc)
f.write(webContent)
f.close
except:
n1=os.path.join(path+'\\'+ 'ASKTOM_MAG_'+'Download_Error.log')
f1 = open(n1, 'w',encoding=enc)
f1.write(url)
f1.close
reqs = requests.get("https://asktom.oracle.com/magazine-archive.htm")
soup = BeautifulSoup(reqs.text, 'html.parser')
for link2 in soup.select(" a[href]"):
src=link2["href"]
durl='https://asktom.oracle.com/'+src
tit =link2.get_text().replace(string.punctuation, " ").translate(str.maketrans('', '', string.punctuation))
print(tit.replace(" ","_"),durl)
Download_ASKTOM_files("c:\\Users\\......\\Downloads\\blogs\\",durl,'UTF-8',tit.replace(" ","_"))
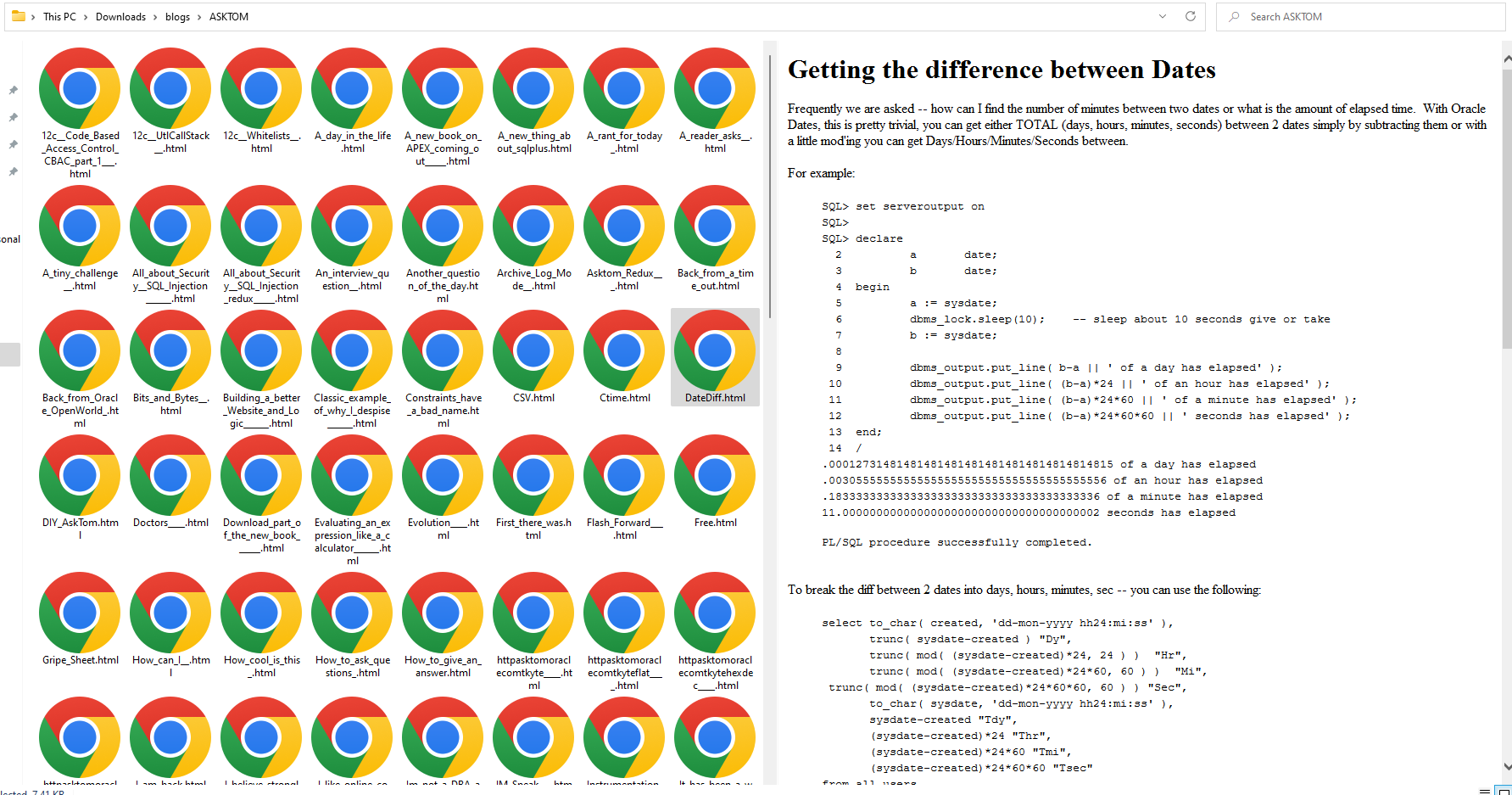
Hope you liked it 🙂
